Architecture Beat the Model: SkillOpt, MiMo Code, and MCP at Scale
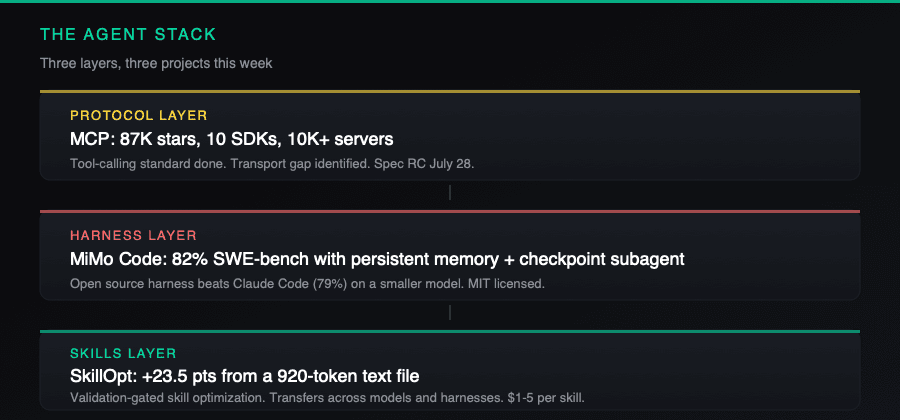
Three open-source projects prove agent architecture beats raw model power: SkillOpt adds 23.5 points from a text file, MiMo Code beats Claude Code, MCP hits 87K stars.
By SpringVanta
Three things happened this week that tell you where AI agent engineering is going. None of them is a new model. All of them are infrastructure.
Microsoft open-sourced SkillOpt, a framework that treats agent skill documents as trainable objects, applying learning rates and validation gates to text files instead of model weights. Xiaomi released MiMo Code, a terminal coding agent that beats Claude Code on SWE-bench while running on a smaller model. And the MCP ecosystem crossed 87,000 GitHub stars with ten official SDKs, making it the default tool-calling protocol for production agents.
The common thread: the model stopped being the bottleneck. The harness, the skills, and the protocol layer are where the gains are now.
Microsoft SkillOpt: agent skills became trainable
Agent skills are markdown files. You write instructions, heuristics, tool-use policies, and failure modes into a .md document, and the agent loads that file into context before executing. The problem has always been that optimizing these files is a guessing game. You tweak a sentence, run the agent, eyeball whether it got better, repeat.
SkillOpt changes that. It treats the skill document as the trainable state of a frozen model, then applies deep-learning discipline to the text itself. An optimizer model analyzes execution trajectories, proposes structural edits (add, delete, replace), and applies them only if they pass a held-out validation gate. The edit budget acts as a learning rate. The rejected-edit buffer prevents the same failed edit from returning.
The results are concrete. On GPT-5.5, SkillOpt added 23.5 accuracy points against a no-skill baseline in direct chat, 24.8 points in Codex CLI, and 19.1 points in Claude Code. It beat every competing method, including human-crafted skills, one-shot LLM generation, TextGrad, and GEPA, across all 52 evaluated combinations of model, benchmark, and harness.
Yifan Yang, the Microsoft Research engineer who built it, told VentureBeat the three failure modes SkillOpt solves: skills drift without step-size control, plausible-looking fixes silently regress without validation, and the same failed edit keeps coming back without negative memory.
What stands out: the optimized skills never exceed 2,000 tokens (median 920), cost $1 to $5 each to train on Claude Sonnet, and transfer across model scales and execution environments. A spreadsheet skill trained inside the Codex loop moved directly into Claude Code and produced a 59.7-point gain over Claude Code's native baseline, with no further optimization.
For operators: this means you can train a skill once, on one provider, and deploy it on another. The skill file is just text. It works with any frozen LLM. No fine-tuning, no extra inference calls at deployment.
Xiaomi MiMo Code: the harness beat the model
MiMo Code is a terminal-native AI coding agent from Xiaomi. It is MIT-licensed, forked from OpenCode, and it outperforms Claude Code on standard benchmarks: SWE-bench Verified 82% to 79%, SWE-bench Pro 62% to 55%, Terminal Bench 2 73% to 69%.
The model running underneath is MiMo-V2.5, which is not a frontier-class model. The benchmark gap comes from the harness.
Three architectural decisions drive the difference:
Persistent cross-session memory. MiMo Code uses SQLite FTS5 full-text search to store project knowledge, architecture decisions, and task progress. When a session resumes, the agent injects relevant memory into context instead of relearning everything. Claude Code, Cursor, and most other agents lose context between sessions.
Checkpoint-writer subagent. An independent subagent monitors context window usage and maintains a structured checkpoint file. When context approaches the limit, the system reconstructs a compressed context from the latest checkpoint plus project memory plus task progress. This is the "auto-compaction" pattern that Zed also shipped this week in v1.7.1, but MiMo Code's implementation is more structured because the checkpoint is a separate agent with its own lifecycle.
Self-improvement commands. /dream scans recent session traces, extracts reusable knowledge into project memory, and removes outdated entries. /distill discovers repeated manual workflows and packages them into reusable skills or subagents. The agent gets better at your specific codebase over time, without you writing new instructions.
MiMo Code supports any OpenAI-compatible API and can import Claude Code credentials in one step. You can use it with MiMo's own model, Claude, GPT, or Qwen.
For operators: the benchmark gap between MiMo Code and Claude Code is roughly five points on SWE-bench. That gap comes entirely from harness architecture, not model capability. If you are choosing an agent platform, the harness matters as much as the model.
MCP at scale: the protocol layer is done
The Model Context Protocol crossed a threshold this week. The servers repository has 87,200 stars. There are ten official SDKs (TypeScript, Python, Java, Kotlin, C#, Go, PHP, Ruby, Rust, Swift). The Python SDK alone sees 164 million monthly downloads. Over 10,000 public MCP servers are registered.
MCP has effectively won the tool-calling layer. A2A (donated to the Linux Foundation) handles multi-agent task coordination. ACP handles lightweight messaging. ANP handles discovery and identity. The stack is converging.
The gap: all of these protocols run over HTTP, which fails for peer-to-peer agent networking across NAT boundaries. A VentureBeat analysis by Vulture Labs' Philip Stayetski argued that the session-layer problem, OSI Layer 5, is the unsolved piece. Projects like Pilot Protocol and libp2p are early candidates. Expect IETF or W3C standards work in the 2027 to 2028 window.
MCP is stable enough to build on now. The spec release candidate is dated July 28, 2026. The old third-party server list has been replaced by the MCP Registry for server discovery.
What this means for your agent stack
If you are building agent workflows, the three layers of your stack each got a major signal this week:
-
Skills layer. Stop hand-tuning skill files. SkillOpt gives you a validation-gated optimization loop for $1 to $5 per skill. The output is a text file that transfers across models and harnesses.
-
Harness layer. The difference between 79% and 82% on SWE-bench is persistent memory and checkpoint management, not model size. MiMo Code is open source and MIT-licensed. Evaluate it against your current agent.
-
Protocol layer. MCP is production-ready. Build on it. Watch for the July 28 spec release candidate. The transport gap is real but does not block current HTTP-based deployments.
The model you pick still matters. But it matters less than the architecture around it. Three independent teams, working on three different layers, proved that this week.
Sources
- Microsoft SkillOpt (VentureBeat)
- SkillOpt GitHub — MIT licensed,
pip install skillopt - MiMo Code (VentureBeat)
- MiMo Code GitHub — MIT licensed
- MCP transport layer analysis (VentureBeat)
- MCP on GitHub