Why 84% of Developers Use AI Tools They Don't Trust
84% of developers use AI coding tools but only 29% trust the output. The context gap is the real bottleneck, and MCP is how teams close it.
By Springvanta
Eighty-four percent of developers use AI coding tools daily. Twenty-nine percent trust the output. The gap between those two numbers is the defining engineering problem of 2026, and the fix is not a better model.
Three developments in the past week converge on the same root cause: AI agents generate plausible code but lack the context to know whether that code is correct for your specific codebase, your specific business rules, and your specific architecture. The fix is context plumbing.
Why Do 84% of Developers Use AI Tools They Don't Trust?
The Stack Overflow 2025 Developer Survey, with 49,000 respondents across 177 countries, found AI coding tool adoption at 84%. Google Cloud's DORA 2025 study puts it at 90%. Neither study disputes the throughput gains: 21% more tasks completed, 98% more pull requests merged per developer.
The trust data runs in the opposite direction. Favorable sentiment dropped from 70% in 2023 to 60% in 2025. Trust in AI-generated code accuracy fell from 40% to 29% in a single year.
CodeRabbit's February 2026 analysis of 470 GitHub pull requests quantifies why. AI-authored PRs averaged 10.83 issues each. Human-written PRs averaged 6.45. The AI multiplier: 1.75× more correctness problems, 1.64× more maintainability problems, 1.57× more security problems.
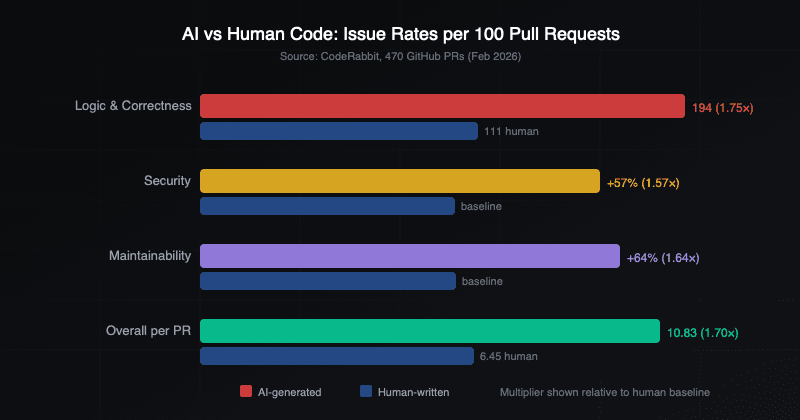
The only category where AI code scored better was spelling in comments.
What Is Context Blindness in AI Coding Agents?
The most expensive AI code failures in 2026 were not coding errors. They were context errors.
Amazon's March 2026 logistics incident is the canonical case. An AI agent generated code following an outdated internal wiki page, corrupting delivery estimates across all marketplaces. The code compiled, tests passed, and 6.3 million orders were destroyed in six hours. The AI had no way to know the wiki had been superseded 18 months earlier.
A mid-size fintech experienced the same pattern. An AI agent refactored a payment-retry routine using a library version that had silently changed its exponential-backoff defaults. Customers were triple-charged before the weekly reconciliation caught it.
CodeRabbit's data shows AI-generated PRs have 1.7× more defects than human PRs across correctness, security, and maintainability. The code looks right. It compiles. It passes linting. And it is subtly, expensively wrong because the agent had no access to the decisions, tradeoffs, and edge cases discussed in meetings, architecture docs, or Slack threads.
This is the context gap: the agent can read your files, but it cannot read the room.
How Is MCP Closing the Context Gap for AI Agents?
Two updates this month attack the context problem from different angles.
Zoom MCP expansion (May 18, 2026): Zoom extended its MCP Server to pipe conversation intelligence into Claude, OpenAI Codex, and other AI tools. Meeting summaries, transcripts, recordings, action items, and notes are now accessible as structured context within coding environments.
Zoom also shipped an OpenAI Codex plugin that lets developers pull meeting intelligence directly into their workflows. Agentic search now connects to Salesforce, Workday, ServiceNow, and 10 other enterprise platforms. The goal: when an agent writes code, it can reference what was actually decided in last Tuesday's sprint planning call.
Claude Code MCP Tool Search (January 2026, ecosystem maturing through May): Anthropic introduced lazy loading for MCP tools. Previously, every connected tool's full documentation loaded into the context window before the user typed a single character. A Docker MCP server with 135 tools consumed 125,000 tokens just for definitions.
Tool Search flips this to an on-demand model. When tool descriptions exceed 10% of available context, Claude Code switches to a lightweight search index and fetches definitions only when needed. Internal benchmarks show an 85% token reduction (from 134K to 5K) and accuracy improvements from 49% to 74% on Opus 4, and 79.5% to 88.1% on Opus 4.5.
Both updates solve the same problem: giving agents access to more relevant context without drowning them in noise.
What Does the 30-60-90 Day Playbook Look Like?
DORA 2025 describes AI as a "mirror and a multiplier." It amplifies what an organization already does. Teams with stable platforms and strong review practices see throughput gains. Teams with fragmented processes see more bugs, more incidents, and more burnout.
The emerging trust-but-verify architecture follows a staged approach:
Days 0 to 30: Measure and stop the bleeding. Instrument incidents-per-PR and change failure rate. Require at least one human review on all AI-generated PRs touching auth, billing, or data access. This is the baseline.
Days 31 to 60: Automate the obvious. Deploy a second-opinion AI code review tool (CodeRabbit, Greptile, or Graphite Diamond). Add SAST with secrets scanning. Enable policy-as-code blocking for critical-severity findings. Open Policy Agent and GitHub branch protection are sufficient for most teams.
Days 31 to 60: Build the context pipeline. Connect MCP servers that carry real business context into your agents. Meeting transcripts (Zoom MCP), ticket history (Jira/GitHub MCP), architecture decision records (internal wiki MCP). The agent that can see why a decision was made writes different code than one guessing from stale documentation.
Days 61 to 90: Close the feedback loop. Connect production telemetry to prompt refinement. Every incident traced to an AI-generated change should produce a guardrail update. Track incident-to-guardrail cycle time as a first-class metric.
What Should Business Leaders Take Away From This Data?
Three numbers frame the decision:
- 84% of your developers are already using AI coding tools, whether or not you have a policy for it.
- 29% of them trust the output, which means 71% are shipping code they would not personally vouch for.
- 242.7% increase in incidents per pull request over two years (Faros.ai/DORA 2025) traces directly to the context gap.
The organizations that treat AI output as a high-velocity, lower-trust input and build verification and context plumbing to match will accumulate the productivity gains without the quality tax. The organizations that treat AI as a magic box will keep appearing in postmortem writeups.
The tools work. The trust has to be engineered.
Sources
- Stack Overflow 2025 Developer Survey (49,000+ respondents, 177 countries)
- Google Cloud DORA 2025 Report (5,000 technology professionals)
- CodeRabbit State of AI vs Human Code Generation Study (470 GitHub PRs, February 2026)
- Cortex 2026 Engineering in the Age of AI Benchmark (50+ engineering organizations)
- Faros.ai Analysis of DORA 2025 Dataset
- Zoom MCP Expanded Capabilities Announcement (May 18, 2026)
- Claude Code MCP Tool Search Update (VentureBeat, January 2026)
- Practical Logix: The AI Code Quality Paradox (May 2026)