62% of AI Citations Don't Name Your Brand
Three June 2026 studies expose how AI search visibility metrics mislead teams: ghost citations, blended click rates, and platform infrastructure gaps that dashboards hide.
By SpringVanta
Three studies landed in the same week, and they all point at the same problem: the numbers most teams collect about AI search visibility are measuring the wrong things. The gap between what the metrics say and what is actually happening is wide enough to misdirect real budget.
A SEMrush study with Kevin Indig published June 9 analyzed 3,981 domain appearances across ChatGPT, Gemini, Google AI Overviews, and Google AI Mode. The headline finding: 62% of the time an AI engine cites a domain as a source, it does not mention the brand by name. Your URL is in the footnote. Your company name is not in the answer.
More than half of your "AI citations" generate zero brand awareness. The user reads the AI's answer, sees a list of sources at the bottom, and never connects the information to you. You are a ghost citation: present in the metadata, absent from the narrative.
Two more studies published the same week explain why this happens and what to do about it. Together they reframe the problem from "how do we get cited more" to "are we measuring the right things at all."
The audience problem: 50% vs 14%
GWI, the consumer research firm whose surveys represent 3 billion individuals, released behavioral data on June 12 that challenges the core assumption behind AI search traffic analysis. Among users who engage with AI-featured search every day, 50% click through to a cited source. Among users who engage once a week or less, that number drops to 14%.
That is a 3.5x difference. Most analytics tools average these two groups together, producing a blended CTR that describes neither audience. You end up with a number like "22% click-through on AI Overview queries" that sounds reasonable and is useless, because it mixes users who treat AI answers as a starting point with users who treat them as an endpoint.
Chris Beer, the GWI senior data analyst who worked on the study, pointed out another layer. Younger users are not passively accepting AI answers. They are more likely than older users to say AI Overviews increased their trust in search results, but also more likely to say it decreased their trust. They are actively evaluating. The daily users clicking through at 50% are not doing it because they trust the AI. They are doing it because they want to verify.
This has a direct implication for content investment. If 50% of daily AI search users click your citation and land on a page that simply restates what the Overview already told them, they leave. Your bounce rate on AI-referred traffic goes up. The fix is to make the cited page deliver something the AI summary cannot: proprietary data, a named expert, a step-by-step process that goes past the conceptual level. Getting cited more, by itself, does not help if the landing page restates what the Overview already said.
The cited pages that retain AI-referred traffic have one thing in common. They answer a specific question with a specific answer. General topic pages with general commentary do not retain. Pages that say "here is exactly how this works, with numbers" do.
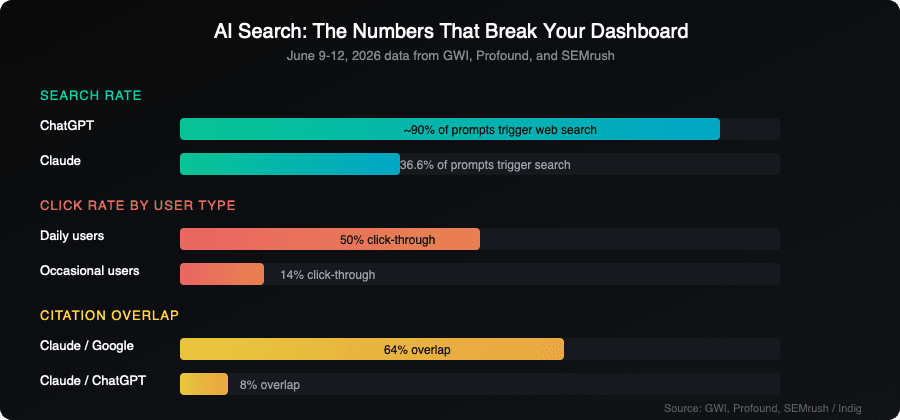
The infrastructure problem: Claude searches 36% of the time
Data shared at a Zero Click by Profound session on June 12 revealed something most teams tracking AI visibility do not know: Claude uses web search in only 36.6% of prompts. ChatGPT searches roughly 90% of the time. These two platforms are not doing the same thing, yet most "AI visibility" dashboards report them side by side as if they were.
When Claude does search, it does not re-rank results. Jonathan Clark, who presented the session data, said Claude appears to use Brave Search's top 10 results directly in its answers. That makes Claude's visibility pathway more predictable than ChatGPT's. It also makes it more tied to traditional search rankings than most GEO advice suggests.
The overlap numbers tell the story. Claude's citations overlap with ChatGPT's in only 8% of cases for the same prompts. Claude's overlap with Google rankings is 64%. If you are tracking your AI visibility using ChatGPT data and assuming it represents the category, you are missing 92% of how Claude sees you.
The prompt types matter too. Claude searches most often when prompts contain "best," "top," "near me," or comparison terms like "X vs Y." Recency-focused prompts trigger search 81% of the time. Ranking-focused prompts trigger it 67%. But prompts like "how does" or "what is" stay in the model's parametric memory. When Claude does not search, it cannot cite web pages. Your fresh content is invisible for those queries.
This is the point where most teams realize their AI visibility tracking has a hole. They are measuring citation presence across platforms without accounting for the fact that different platforms search at different rates, use different infrastructure, and answer from different memory systems.
The memory problem: one score, two systems
Duane Forrester, writing in Search Engine Journal on June 11, gave the underlying problem a name: memory posture. Every AI engine leans on one of two memory systems. Parametric memory is knowledge baked into the model during training, frozen until the next training run. Retrieval is live web content pulled in at the moment someone asks.
Perplexity and Google AI Overviews retrieve on almost every query. ChatGPT, Claude, Copilot, and the Gemini app decide per query. And the decision is not stable. One clickstream study of ChatGPT found web search usage swinging between 15% and 66% of sessions over the study window, moving as the underlying models were updated.
Forrester's argument is blunt: a single AI visibility score is a category error. It averages parametric standing and retrieval standing into one figure, but those two things move independently, reward different work, and fail in different ways. You cannot manage what you have flattened.
A parametric problem, like an outdated brand description baked into a training run, cannot be fixed by publishing a correction today. You influence the next training window by getting consistent, corroborated content in place now so the accurate version of your story is the one that gets learned. A retrieval problem is different. It requires answering the fan-out sub-questions that agentic retrieval generates, structuring pages for clean extraction, and strengthening corroboration across third-party sources.
These are different workstreams with different timelines and different success metrics. Collapsing them into "AI visibility" ensures you optimize for neither.
What to actually do
Start with a memory posture audit. For each engine that matters to you, determine whether your brand is carried by parametric memory or retrieval. If it is parametric, your timeline is the next training run. If it is retrieval, your timeline is your next content update. Then check whether your citations actually name your brand. Pull them from each platform and read them. If your URL appears but your company name does not, you are a ghost citation. Make your brand name structurally prominent in the content the AI extracts: titles, headings, first sentences.
Finally, track the search infrastructure underneath each AI platform. Claude runs on Brave Search. ChatGPT runs on Bing. Google AI features run on Google's index. Your rankings in each of those underlying engines predict your visibility in the AI layer on top. Track Brave rankings if Claude matters to you. Track Bing rankings if ChatGPT matters. Stop assuming Google rankings translate everywhere, even though Claude's 64% overlap with Google suggests they help more than most people assume.