AI Search Engines Don't Agree on What to Cite
AI search engines share only 1.4% of cited URLs for the same query. The May core update tightens Google, but ChatGPT, Perplexity, and Claude follow different rules.
By Springvanta
Google's May 2026 core update started rolling out on May 21, two days after I/O. Early data from Search Engine Roundtable, Search Engine Land, and community reports shows the same pattern the March update established: AI content farms losing 60-90% of traffic, aggregator sites dropping from "near me" queries, specialist publishers gaining ground.
That's half the story. The other half is more uncomfortable.
Even if you survive this update and rank well on Google, the research says you're probably invisible on every other AI search engine. Not because your content is bad, but because ChatGPT, Perplexity, Gemini, and Claude pull from entirely different source pools for the same query.
The 1.4% problem
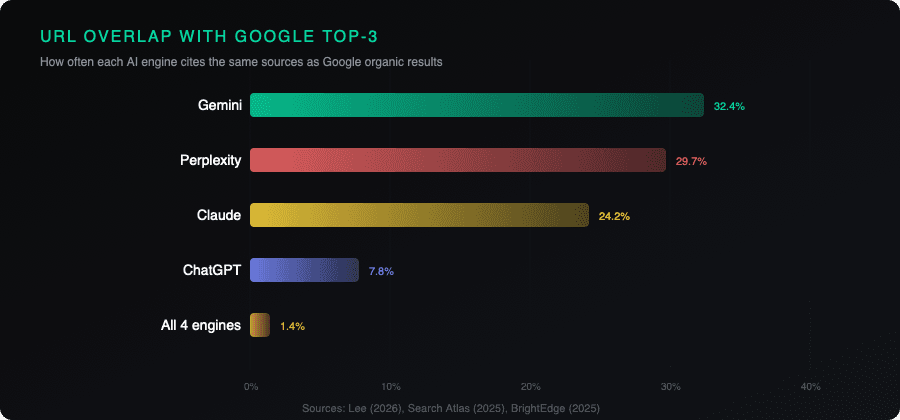
Anthony Lee's April 2026 study tested 19,556 queries across ChatGPT, Claude, Perplexity, and Gemini. The cross-platform URL overlap was 1.4%. That means if ChatGPT cites 5 sources for a query and Perplexity cites 5 for the same query, the expected number of shared URLs is less than one.
A separate analysis by Search Atlas covered 5.5 million LLM responses across 748,425 queries. On 35-40% of those queries, ChatGPT, Perplexity, and Gemini shared zero cited domains. Not different rankings of the same sources. Different sources entirely.
BrightEdge's 16-month study of AI Overview citation patterns found that 45.5% of Google AI Overview citations come from pages outside the organic top results. Ranking well on Google is not a guarantee of being cited, even by Google's own AI.
Why the engines disagree
The divergence isn't random. It's architectural.
Perplexity searches the live web before every answer (RAG). ChatGPT pulls from Bing's index when web search is triggered. Google AI Mode and Gemini use Googlebot's crawl. Claude relies on Brave Search. Each crawler sees a different version of the web. Each ranking system weights different signals. Perplexity rewards freshness 3.3x more than Google does. ChatGPT leans on whatever dominated its training data. Google's AI overvalues YouTube and Google-owned properties.
Lee's study also found that schema type matters more than schema presence. Product schema (OR = 3.09), Review schema (OR = 2.24), and FAQPage schema (OR = 1.39) all increased citation odds. Generic Article schema actually decreased them (OR = 0.76). This is a detail most "AI SEO" advice misses.
The May core update tightens Google. The other engines don't care.
Google's update targets AI content farms and rewards what Google calls "non-commodity content," meaning content with original insights, first-hand experience, or proprietary data that Google's AI can't synthesize on its own. Google's ranking systems now use Gemini-based quality models, tying the organic algorithm closer to the AI Overview citation engine.
That alignment matters for Google. It doesn't help you on Perplexity or ChatGPT.
Perplexity's crawler (PerplexityBot) maintains its own index with a 3.3x freshness bias compared to Google. A page updated five minutes ago can surface on ChatGPT within minutes if Bing has it, but Perplexity takes 1-7 days to crawl new content through its index. Google AI Mode only cites what Googlebot has already indexed.
These timelines don't overlap. A content strategy built around Google's crawl schedule will look stale on Perplexity. A strategy built around Perplexity's freshness requirements may not have the authority signals Google's AI Overviews demand.
What works where
The research points to a handful of things that work across platforms, and a handful that only work on one.
Works everywhere:
- Server-side rendering (ChatGPT and Claude's bots don't execute JavaScript)
- Self-referencing canonicals (OR = 1.92 for citation odds)
- High content-to-HTML ratio
- Front-loading key claims in the first 30% of the page
- XML sitemaps submitted to Google Search Console AND Bing Webmaster Tools
- Getting earned media coverage in publications that AI engines cite (85.5% of AI citations come from earned media, per Muck Rack's analysis of 1M+ prompts)
Platform-specific:
- For Perplexity: keep content fresh (update dateModified in sitemaps), use structured data tables and numbered lists
- For ChatGPT: make sure Bing has indexed you; server-side rendering is non-negotiable
- For Google AI Mode: traditional SEO fundamentals, YouTube presence for video-rich queries
- For Claude: focus on well-sourced, balanced content from institutional domains
The tracking gap
Here's the part that should bother you. Goodfirms' April 2026 survey of 100 marketing practitioners found that 89% of brands appear in AI search results, but only 14% are tracking their AI citation visibility. Most brands have no idea which engines cite them and which don't.
Cloudflare's 2025 traffic analysis found ClaudeBot crawls content at 38,065 times the rate it sends users back to source sites. Your content is being consumed by AI crawlers constantly. Standard analytics don't register this. Google Search Console doesn't show it.
If you're only monitoring Google rankings, you're seeing roughly one-third of your actual search visibility.
Sources
- Lee, A. (2026). "Query Intent and Google Rank as Joint Predictors of AI Citation." Preprint v6.
- Machine Relations / AuthorityTech (2026). "How AI Search Engines Choose What to Cite." Analysis of Search Atlas 5.5M response dataset.
- BrightEdge (2025). "AI Overview Citation Overlap After 16 Months." 9-industry longitudinal study.
- Goodfirms / GlobeNewswire (April 2026). "Only 14% of Marketers Track AI Search Citations."
- Muck Rack (July 2025). "PR in the Generative Engine Optimization Era." 1M+ prompt analysis.
- Search Engine Roundtable (May 21, 2026). "Google May 2026 Core Update Is Rolling Out."
- Cloudflare (August 2025). "AI Crawlers and Click Data."
- danishashko/ai-citation-patterns (May 2026). 153,425 citations across 5,000 queries, 6 platforms.