The Bottleneck Moved From Coding to Everything Else
Code with Claude SF 2026 doubled rate limits, locked in 220K GPUs via SpaceX, and proved that review and verification—not writing code—are now the constraint.
By SpringVanta
On May 6, a few thousand developers filed into SVN West in San Francisco for Anthropic's second Code with Claude conference. They left with higher rate limits, a clearer picture of where agent infrastructure is headed, and one uncomfortable realization: the slow part of shipping software is no longer writing the code.
Three announcements that matter
Anthropic kept the launches focused and practical—no new model, no Mythos general availability. Three things actually shipped: Rate limits doubled across all paid plans. Claude Code's five-hour rolling limits are now twice what they were. Pro and Max users also lost peak-hour throttling entirely. For teams running long-horizon agent sessions,multi-repo refactors, day-long autonomous loops, this is the biggest capacity change since Claude Code launched. The SpaceX Colossus 1 deal. Anthropic now controls the entire Colossus 1 data center in Memphis, Tennessee: over 300 megawatts and 220,000 NVIDIA GPUs coming online within the month. CEO Dario Amodei disclosed that demand has grown 80x so far in 2026. The timing,rate-limit doubling on the same day as the capacity announcement, was not a coincidence. Multi-agent orchestration and Claude Code routines. Managed Agents, which entered public beta in April, gained two capabilities: an orchestrator that dispatches subtasks across a fleet of specialized worker agents, and routines,recurring task templates that run on a schedule. Think dependency audits, code reviews, or documentation drift checks that run overnight without human intervention. Ten financial-services agent templates also shipped simultaneously as plugins for Claude Cowork, Claude Code, and as cookbooks for Managed Agents. One artifact, three surfaces.
The context window is still a box
One of the most grounded sessions came from Daisy Hollman, a Member of Technical Staff at Anthropic, who spent her workshop making a single point: context windows are not getting bigger anytime soon.
The practical implication is that choosing what goes into that fixed box is now a core engineering skill. Stuffing a CLAUDE.md with every convention your team uses sounds reasonable until you realize you pay for all of it on every turn,worse results, higher cost.
MCP tool descriptions are a particular trap. Twenty MCP servers, each exposing fifteen tools, means your prompt is mostly schema definitions before Claude reads a single line of code. If you already have a CLI that does the job, let Claude shell out to it rather than wrapping it in an MCP server.
The standout recommendation: hooks are the only abstraction that consume zero context until they fire. Hooks act like real-time linter warnings,small corrections injected at the moment of a mistake, not caught later in review. For any team building agent workflows, this is the highest- context optimization available today.
Brad Abrams, who leads product on the Claude Platform, put a number on it: aim for at least an 80% prompt cache hit rate before optimizing anything else. Cursor, Replit, Perplexity, and Claude Code itself all run caching rates in the 90s.
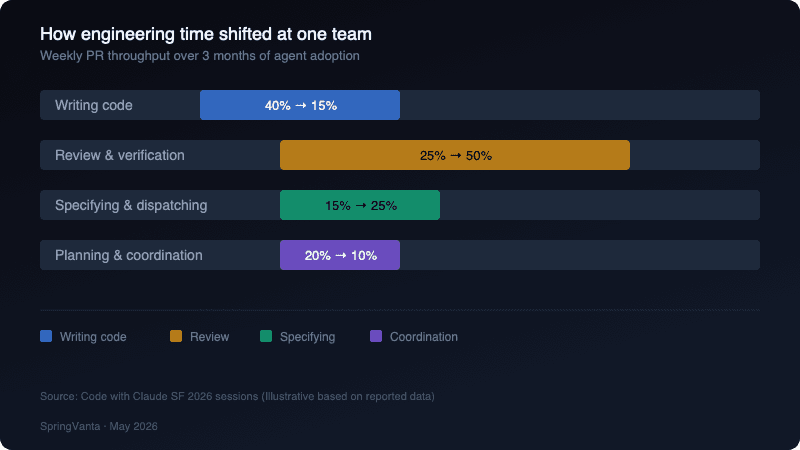
The bottleneck has moved
Fiona Fung, who runs AI-native engineering at Anthropic, stated it directly: "the bottleneck moved from coding to everything around coding." One team showed their weekly PR throughput climbing from roughly 500 merged PRs in January to 1,150 by March,a 300% increase in three months. The downstream effect was not happiness about velocity; it was panic about their single documentation engineer becoming the new bottleneck. Jarred Sumner, creator of Bun, demoed Robobun,an autonomous Claude Code agent that now makes more commits to the Bun codebase than Jarred himself. His review workflow: let CodeRabbit and Claude Code debate the same PR from different angles, iterate in the background, and review only the final output. The pattern is consistent across every session: engineering work is shifting from writing and reviewing code to specifying work, dispatching agents, and evaluating what comes back.
What this means for teams building with AI
The conference made several implications clear for any team evaluating or running AI agent tooling: Verification is the new bottleneck. Teams that invest in shifting verification left,automated testing, hook-based guardrails, agent-driven code review, are the ones that scale. Those that don't will drown in agent output they can't trust. Process redesign beats tool adoption. Anthropic has effectively killed the "design doc before any code" ritual internally. When teammates disagree on a direction, the fastest resolution is having Claude prototype both options and reviewing the artifact. Building is cheaper than arguing. Cache efficiency is a first-order concern. Every production agent should target 80%+ prompt cache hit rates. Unused tool schemas, raw tool output, and unoptimized data formats are burning context budget and money simultaneously. Hooks over CLAUDE.md bloat. The most context-efficient way to guide agent behavior is hooks that fire only when needed,not static instructions that consume tokens on every turn. Run agents overnight. Daisy Hollman's advice was blunt: "You should be running agents overnight." With Opus 4.7 capable of autonomous multi-hour sessions, the teams that dispatch async work at end-of-day and review results in the morning are pulling ahead.
The Week 19 Claude Code release
Alongside the conference, Claude Code shipped releases v2.1.128 through v2.1.136 with practical improvements: plugins can now load from.zip archives and URLs via --plugin-url, cross-project history search with Ctrl+R, hard-deny rules for auto mode, and roughly 3x reduction in cache_creation token cost from sub-agent progress summaries hitting the prompt cache.
The OAuth reliability fixes alone,parallel sessions no longer dead-end at 401, MCP refresh tokens no longer lost during concurrent refreshes, signal how much production traffic Claude Code is handling.
What wasn't said
No Mythos general availability. No new model below Mythos. No Sonnet 5 or Haiku 5. No pricing changes for the API. The message was deliberate: Anthropic is preparing for sustained scale at the current model lineup, not racing to ship something new. Claude Security, which entered public beta for Enterprise customers on April 30, received zero stage time,an omission that surprised several attendees given the accelerating role of AI in both vulnerability discovery and defense.
Why this matters for business automation
The shift from "coding as bottleneck" to "everything around coding as bottleneck" mirrors what's happening in business operations more broadly. The teams seeing the biggest gains from AI are not the ones that simply hand tasks to agents. They're the ones that redesign the surrounding processes,review cycles, approval flows, quality gates, to handle dramatically higher throughput. For SpringVanta buyers evaluating AI intake forms, voice agents, or lead qualification automation, the lesson transfers directly: the value isn't in replacing one step. It's in redesigning the workflow around what agents can now do continuously, asynchronously, and at scale.
Sources: