JetBrains Benchmarked Its Own Agent and Picked Codex Instead
JetBrains picked Codex over Junie with transparent data. Cursor built a marketplace leaderboard. Claude Code hardened MCP. Three layers of agent management shipped in 72 hours.
By SpringVanta
JetBrains spent a year building Junie, its own AI coding agent. On June 25, it recommended OpenAI's Codex instead.
That sentence deserves some unpacking, because it says more about where AI coding tools are going than any product launch this month. JetBrains ran a transparent, reproducible benchmark across 353 real engineering tasks, published the full methodology, and concluded that Codex with GPT-5.4-mini medium reasoning edges out Junie with Gemini 3 Flash on solve rate (39.9% vs 39.1%) — but lost on cost ($0.14 vs $0.11 per task) and latency (170s vs 148s). The offline numbers were close enough that the decision came down to an online A/B test with real users. Codex won on activation and churn. JetBrains made it the default.
This landed in the same 72-hour window as two other stories that, taken together, describe a market that has quietly moved past "which agent should I use?" to "how do I manage the ones I already have?"
JetBrains picked a default agent with real data
The JetBrains benchmark is worth looking at closely, not because the results are surprising, but because the methodology is. Most agent comparisons you see online are Twitter posts with vibes-based rankings. JetBrains built a dataset from 353 real software engineering tasks across Java, C#, and Python — bug fixes, feature work, enhancements — each grounded in a real codebase with automated tests that verify the result. The data lives in their open Developer Productivity AI Arena (DPAIA) repository, so anyone can reproduce it.
Three things stand out from the results.
First, the gap between agents is small and inconsistent. Codex won the aggregate solve rate by 0.8 percentage points. But in Java specifically, Junie actually scored higher (45.2% vs 43.9%). In C#, Codex dominated (62.6% vs 58.7%). In Python, both were underwhelming (20.2% and 15.6%). A 20% solve rate on Python tasks means four out of five attempts fail. The idea that any single agent is "the best" depends entirely on which language and task type you happen to be working in.
Second, JetBrains set a cost ceiling before ranking quality. Any setup that would push more than 2% of users over $20/month in JetBrains AI tokens was eliminated. That is a procurement constraint, not a benchmark metric. It reflects how real teams actually adopt these tools — the question is never just "which agent solves more tasks" but "which agent solves more tasks at a price my finance department will approve."
Third, the offline benchmark alone was not enough to decide. The solve rates were within margin of each other, so JetBrains ran a live A/B test tracking activation and churn. Codex won. The methodology page notes this is not a permanent decision — JetBrains will re-evaluate as models evolve. That is the right framing. The interesting part is that they committed to a transparent, data-driven selection process at all.
Cursor built governance for agent tooling
If JetBrains is solving "which agent should I start with," Cursor 3.9 (shipped June 22) is solving a different problem: once you have agents, what are they allowed to use?
The update introduces a Customize page that brings plugins, skills, MCP servers, subagents, rules, commands, and hooks into a single management interface. You can configure these at the user, team, or workspace level. A marketplace leaderboard shows which plugins, skills, and MCPs are most popular across your team — with usage counts and the ratio of agent-initiated versus human-initiated invocations over the past 30 days.
That last detail matters more than it looks. Knowing that a teammate's agent has been calling a specific MCP server 200 times this month is a governance signal. Knowing that 90% of those calls were agent-initiated (the model decided to use it) versus human-initiated (the developer explicitly asked for it) tells you something about what your codebase is actually doing when nobody is watching.
Team marketplaces now support imports from GitLab, Bitbucket, and Azure DevOps, not just GitHub. Plugin canvases — prebuilt shared dashboards — ship with Atlassian and Hex integrations. The broader pattern: Cursor is building the control plane for agent extensibility. Not "which agent" but "what is each agent allowed to touch, and who approved it."
This comes on top of Cursor 3.8 (June 18), which shipped Automations with a /automate skill for plain-language workflow creation, five new GitHub triggers, a Slack emoji trigger, and computer use for cloud agents. The cadence is fast — two major releases in four days — and both push in the same direction: agent workflows that run without a developer at the keyboard, governed by tooling that gives the team visibility into what those workflows do.
Claude Code hardened the plumbing
While JetBrains picked a default agent and Cursor built governance layers, Claude Code shipped the least glamorous but arguably most important update of the three. Version 2.1.191 (June 25) focuses on reliability fixes that address the kind of problems you only hit when agents run for hours on real work.
The /rewind command restores context after /clear — a small change that fixes a real workflow problem. Developers were losing session context when they cleared the terminal, which meant restarting complex agent tasks from scratch. Background agent stops are now permanent instead of resumable, which prevents zombie sessions from consuming resources. Streaming output coalescing at 100ms intervals cuts CPU usage by roughly 37% during active agent runs.
The MCP fixes are the ones I would flag for any team running agents in production. The protocol now retries failed MCP connections with exponential backoff and supports headless OAuth flows — meaning MCP servers that require authentication can connect without a browser popup, which is essential for CI/CD and remote environments. Comma-separated hook matchers were fixed, so you can now write "Bash,PowerShell" in a hook config and it actually matches both.
None of these are headline features. They are the kind of fixes that separate a tool you experiment with from one you can depend on.
What the convergence means
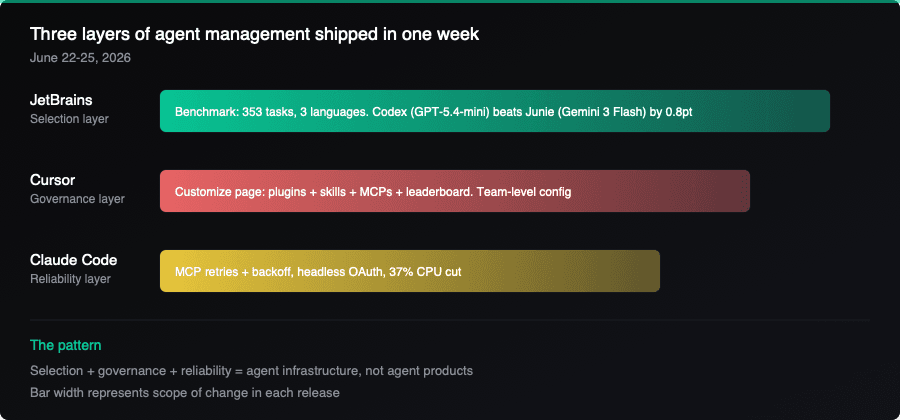
Three things happened in the same week, and they map to three layers of the same problem:
- Selection — JetBrains published a transparent benchmark and picked a default agent based on cost-constrained solve rate data.
- Governance — Cursor centralized plugin, skill, and MCP management into a team-level control plane with usage analytics.
- Reliability — Claude Code hardened MCP connectivity, session management, and resource usage for long-running agent work.
If you are evaluating AI coding tools for a team right now, the relevant question has shifted. It is no longer "which single agent should we standardize on" — the JetBrains benchmark shows that the answer changes by language and task type, and the gap between top agents is less than a percentage point. The question is whether your tooling gives you the infrastructure to run multiple agents, manage what they can access, and keep them running when things break.
JetBrains said it directly: "This isn't a permanent decision." They will re-evaluate as models evolve. That is the right instinct, and it is the operating assumption for anyone building an agent stack in mid-2026. The agents will change. The infrastructure you build around them — selection criteria, governance controls, reliability engineering — is what compounds.
Sources
- JetBrains: Introducing the Recommended Agent in AI Chat (June 25, 2026)
- Cursor 3.9 Changelog (June 22, 2026)
- Cursor 3.8 Changelog: Automations (June 18, 2026)
- Claude Code v2.1.191 GitHub Release (June 25, 2026)
- Web Developer: JetBrains Junie GA Coverage (June 17, 2026)
- Tessl: Cursor's Leaderboard Analysis (June 24, 2026)