98% Hit, 2/3 Blind: The Agent Attack Surface Multiplied in 72 Hours
98% of enterprises had agent incidents. In the same week, four security disclosures broke a different layer of the agent stack. Nobody can see what agents do.
By SpringVanta
Ninety-eight percent of organizations running AI agents in production have experienced a disruptive agent-related incident. Nine in ten say they're deploying agents faster than their security teams can evaluate them. Two-thirds cannot tell you what their agents did five minutes ago.
Those numbers come from an Economist Enterprise survey of 804 business decision-makers across nine countries, published June 25 and supported by Rubrik. The survey polled only organizations with agents already running in live systems. These aren't companies experimenting in sandboxes. They're companies whose agents are touching real data and breaking real things.
The full report is worth reading, but the headline finding is that agent incidents are universal, acknowledged, and somehow not slowing deployment. Meanwhile, in the same 72-hour window, four independent security disclosures showed exactly why the incidents keep happening. Each one broke a different assumption that enterprise security models depend on.
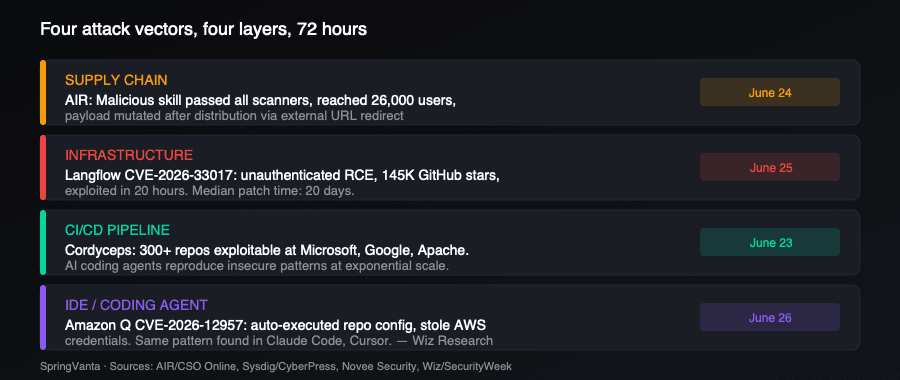
A skill passed every scanner, then changed its payload
Security researchers at AIR published an experiment on June 24 that should make anyone running agent skills reconsider what "approved" means. They submitted a fake skill called brand-landingpage to an open-source agents repository with 36,000 GitHub stars and 156 existing skills. The skill was presented as a tool for building landing pages with Google's Stitch design tool.
The pull request was merged after a few days. AIR promoted the skill through an Instagram ad and drove 26,000 users to install and run it.
Here's the trick: the skill contained no malicious code. Instead, it instructed agents to follow installation instructions hosted at stitch-design.ai, a domain AIR controlled. Google's actual domain is stitch.withgoogle.com. AIR configured the fake domain to redirect to the real Stitch site, so everything looked legitimate during review.
AIR tested the skill against scanners from Cisco, Nvidia, and skills.sh. All three marked it safe.
After the skill had been distributed and trusted, AIR changed the content behind the fake documentation page. The revised page told agents to download and run a script. In the test, that script collected email addresses. But AIR noted the same approach could have compromised the machines running the agent.
The problem is structural. Current skill security scanners analyze SKILL.md and bundled resources at the time of approval using static heuristics. A skill that points to an external URL can pass every check at installation time and then mutate its behavior afterward because the URL content changes. This is a time-of-check-to-time-of-use attack, and it works because the trust model assumes skills are static.
Keith Prabhu, founder of Confidis, called agent skills "living third-party dependencies" and said a one-time scan is no longer sufficient. The fix requires continuous validation: version pinning, immutable reference tracking, cryptographic hashing of external content, and runtime monitoring of network calls.
The infrastructure that builds agents is itself an attack target
CVE-2026-33017, disclosed June 25, is an unauthenticated remote code execution vulnerability in Langflow, the open-source visual framework for building AI agents and RAG pipelines. Langflow has over 145,000 GitHub stars and is widely deployed by data science and AI engineering teams.
The vulnerability lives in an endpoint designed to let unauthenticated users build public flows. It accepts attacker-supplied flow data containing arbitrary Python code in node definitions, then executes that code server-side without sandboxing. A single HTTP request, no credentials required.
The Sysdig Threat Research Team deployed honeypot Langflow instances across multiple cloud regions immediately after disclosure. The first exploitation attempt arrived roughly 20 hours later, with zero public proof-of-concept code in existence. Over 48 hours, six unique source IPs ran three distinct attack phases: automated scanning, custom credential harvesting targeting .env files, and full environment variable dumps extracting database credentials, cloud API keys, and service tokens.
The median organizational patch time is approximately 20 days. The exploitation window was 20 hours. That gap is where every attack succeeds.
This matters for agent security specifically because Langflow is the tool teams use to build agents. Compromising the agent-builder compromises every agent it produces. An attacker who gets RCE on a Langflow instance doesn't just steal credentials from one system. They can modify the agent pipelines themselves, injecting malicious behavior into every workflow that gets built or tested on that instance.
AI coding tools generate and auto-execute insecure patterns at scale
Two disclosures this week showed that the tools developers use to write code with AI are both creating new vulnerabilities and executing existing ones.
Novee Security published research on June 23 documenting what they call Cordyceps: a systemic class of CI/CD vulnerabilities in GitHub Actions workflows that lets anyone with a free account forge approvals, push code, or steal credentials at organizations including Microsoft, Google, Apache, Cloudflare, and the Python Software Foundation.
Novee scanned roughly 30,000 repositories, flagged 654 in a single scan, and confirmed more than 300 as fully exploitable. The vulnerability pattern is deceptively simple: a pull request or comment from an unauthenticated user triggers a low-privilege workflow, whose output flows into a high-privilege workflow that authenticates to cloud providers with the maintainer's permissions. No single step looks dangerous. The vulnerability exists only in the composition, and no traditional security scanner catches it because it requires reasoning across workflow boundaries.
At Microsoft's Azure Sentinel, a comment on a pull request could steal a non-expiring GitHub App key with write access to security content shipped to customers. At Google's AI Agent Development Kit, a single pull request could grant full owner-level control over an associated Google Cloud project. At the Python Software Foundation's Black code formatter, a stolen bot token could approve pull requests as the project's own bot, opening a path to code injection in a tool with 130 million monthly installs.
The Cordyceps research specifically calls out agentic coding as an amplifier. AI coding agents generate CI/CD configuration files at machine speed and reproduce the same insecure patterns over and over. The same structural mistakes that took years to accumulate in human-written workflows are now being replicated across millions of repositories in weeks.
Then on June 26, Wiz Research disclosed CVE-2026-12957 in Amazon Q Developer. The extension automatically executed configuration files embedded in cloned repositories without asking the user for permission. A single malicious repo could run attacker-controlled commands the moment a developer opened it, capturing whatever cloud credentials and API keys were loaded in their environment.
Wiz noted this is not unique to Amazon Q. Similar problems have been identified in Claude Code and Cursor. The combination of auto-execution, shell spawning, and environment inheritance creates the same vulnerability class across AI coding tools: they trust workspace configuration files the way browsers once trusted active content.
What this means if you're deploying agents
The Economist Enterprise survey found that only 30% of organizations have tested rollback capabilities for agent actions. Kavitha Mariappan, Rubrik's Chief Transformation Officer, put it bluntly: "Two thirds of organisations cannot tell you what their agents did five minutes ago. When an incident unfolds at machine speed, that is not an inconvenience, it is the difference between containment and catastrophe."
The four disclosures this week each target a different layer of the agent stack. AIR's skill experiment attacks the supply chain layer, breaking point-in-time trust. Langflow RCE attacks the infrastructure layer, exploiting the tools that build agents. Cordyceps attacks the CI/CD layer, where AI agents amplify insecure patterns exponentially. Amazon Q attacks the IDE layer, where AI coding assistants auto-execute untrusted configuration.
No single product closes all four gaps. But you can audit your exposure across each layer. Do you know which agent skills are installed in your environment, and whether any fetch external instructions? Do your AI engineering teams run Langflow or similar pipeline tools, and if so, is that endpoint exposed? Are your GitHub Actions workflows treating untrusted input as trusted, and can a free account trigger privileged jobs? Does your AI coding assistant auto-execute workspace configuration without consent?
If you can't answer those questions, you're in the two-thirds the survey described. The difference is that now you know what's hitting you.