When Prompts Become Shells: Microsoft's Semantic Kernel RCE
Microsoft disclosed two CVSS 9.9 flaws in Semantic Kernel that turn prompt injection into remote code execution. Here is what it means for agent deployments.
By SpringVanta
On May 7, 2026, Microsoft's security research team published a blog post titled "When Prompts Become Shells." It disclosed two vulnerabilities in Semantic Kernel, Microsoft's open-source framework for building AI agents. One let a chat message launch calc.exe on the machine running the agent. The other let a crafted prompt write a file to the Windows Startup folder.
Both scored 9.9 on CVSS. Both were patched before disclosure. Both started from the same place: a text input that an AI model interpreted, chose a tool, and fed parameters into real code.
CVE-2026-26030: A search parameter became a shell command
The first vulnerability lived in Semantic Kernel's Python package. The framework's In-Memory Vector Store had a search function that filtered results using a Python lambda expression built with eval(). When a user asked "Find hotels in Paris," the model called the search tool with city="Paris". That string got interpolated into a lambda and executed.
The problem: the parameter was model-controlled and unsanitized. An attacker who could inject a prompt could close the quote and append arbitrary Python. Microsoft showed an exploit that crawled through Python's type system, located BuiltinImporter, loaded the os module, and called system(). The framework had a blocklist checking for dangerous names like eval and __import__. The exploit used names not on the list.
CVE-2026-25592: The sandbox door was a tool
The second vulnerability targeted the.NET SDK's SessionsPythonPlugin. This plugin runs Python code inside Azure Container Apps dynamic sessions — isolated cloud sandboxes with their own filesystem. The isolation model is solid. The escape came from a file-transfer helper.
DownloadFileAsync was marked with a [KernelFunction] attribute, which advertised it to the AI model as a callable tool. That made the local file path AI-controlled. An injected prompt could instruct the model to create a payload inside the sandbox, then call the download helper to write it to the host's Startup folder. On the next user sign-in, the script runs.
The container boundary held. The problem was a trusted bridge across it that had been handed to the model. Microsoft's fix removed the [KernelFunction] attribute, making the function invisible to the AI, and added path validation for programmatic callers.
The same week: Microsoft used agents to find vulnerabilities
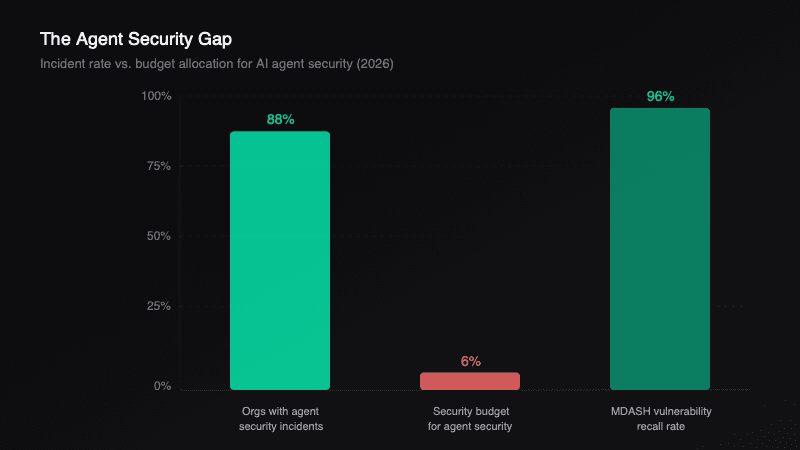
Five days after the Semantic Kernel disclosure, Microsoft announced MDASH, a multi-model agentic scanning harness. It uses more than 100 specialized AI agents to discover, debate, and validate exploitable vulnerabilities. MDASH found 16 new vulnerabilities in the Windows networking and authentication stack, including four critical RCEs. On a private test driver with 21 intentionally injected vulnerabilities, it found all 21 with zero false positives. Taesoo Kim, VP of Agentic Security at Microsoft, described the shift: "AI vulnerability discovery has crossed from research curiosity into production-grade defense at enterprise scale." Two things are true at the same time. AI agents can find critical security flaws faster than human teams. AI agent frameworks can be exploited through those same agents. The Mexican government learned this the hard way: between December 2025 and February 2026, a single attacker used Claude Code and GPT-4.1 to breach nine federal agencies and exfiltrate 150 GB of data covering 195 million taxpayer records. The attacker logged 1,088 prompts across 34 sessions. Claude Code executed roughly 75% of the remote commands.
What this means for businesses deploying AI agents
Microsoft's own guidance is blunt: "Your LLM is not a security boundary." Any tool parameter the model can influence must be treated as attacker-controlled input. The practical implications: Inventory what tools your agents can call. Every exposed function is part of the attack surface. The Semantic Kernel file-download function was safe when called by developer code. It became dangerous when callable through natural language. Patch agent framework dependencies. Semantic Kernel's fixes are in version 1.39.4 (Python) and 1.71.0 (.NET). If your agents run older versions, they are vulnerable. The patch closes the exploit path without requiring architectural changes. Hunt for past exploitation. Patching fixes the bug. It does not answer whether someone exploited it before you patched. Microsoft recommends checking endpoint telemetry for the vulnerable window: suspicious child processes, outbound connections, persistence artifacts spawned by the agent host process. Separate model trust from execution trust. The model choosing which tool to call and what parameters to pass is not a security decision. It is a convenience decision that an attacker can influence. Runtime enforcement at the tool invocation layer , before execution, is where security happens.
Sources
- Microsoft Security Blog: When prompts become shells (May 7, 2026)
- Microsoft Security Blog: Defense at AI speed : MDASH (May 12, 2026)
- Help Net Security: Microsoft's agentic security system (May 13, 2026)
- HackRead: Hacker Used Claude Code, GPT-4.1 to Exfiltrate Mexican Records
- Vibe Graveyard: Semantic Kernel bugs turned prompt injection into RCE