The Model Is Not the System. The Controls Are Missing.
Every frontier model fails the majority of SRE incidents. Runtime authorization barely exists. Enterprises are rebuilding their first agents. Three data points, one gap.
By Springvanta
The benchmark that killed the optimism
On May 30, IBM Research and Artificial Analysis published ITBench-AA, the first independent, reproducible benchmark for agentic enterprise IT tasks. They ran 59 real-world Kubernetes incident scenarios against every major frontier model.
Every single one failed the majority of them.
Claude Opus 4.7 led the pack at 47%. GPT-5.5 came in at 46%. Gemini 3.1 Pro Preview managed 30%. The ceiling, the best any model can do right now on a task that looks like what actually shows up in an on-call queue, is below a coin flip.
This is not a vendor benchmark tuned for a demo. IBM built the evaluation infrastructure on CrewAI, deployed it to Kubernetes, and published the framework open-source. Forty of the 59 tasks are public. Nineteen are held-out, meaning the models had never seen them before evaluation. Any team can submit to the Artificial Analysis leaderboard and reproduce the results.
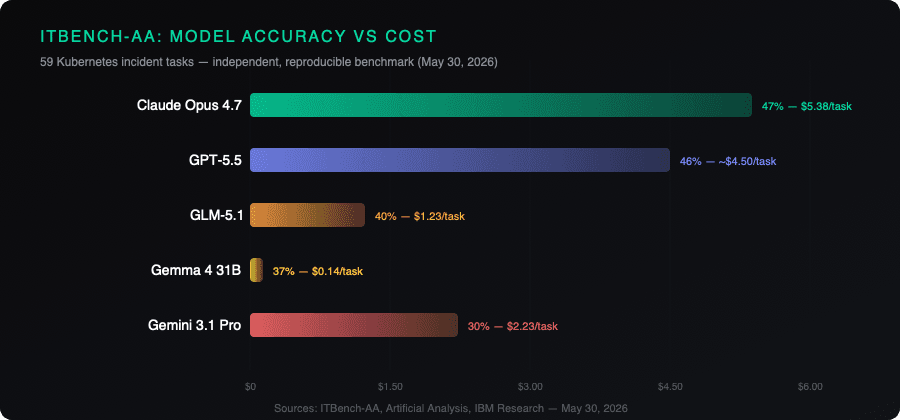
The number that should make operations teams uncomfortable is the cost table. Gemma 4 31B, an open-weights model, scored 37% at $0.14 per task. Gemini 3.1 Pro Preview, a closed Google frontier model, scored 30% at $2.23 per task. The open-weights model was more accurate and 16x cheaper. Claude Opus 4.7's 47% accuracy costs $5.38 per task, a 38x premium over Gemma for a 10-point accuracy gain.
Whether that premium is worth it depends on what happens after the model gives its answer. Which turns out to be the part nobody built controls for.
The part nobody built
Two days before the ITBench-AA results went live, Cerbos CPO Alex Olivier published a piece that frames the governance gap precisely.
The line that stuck: "Frameworks govern what models say. Almost nothing governs what agents do."
Olivier identifies three gaps. The first is identity. Most enterprises issue one long-lived API key per "the agent" and treat every spawned instance as the same actor. When one agent spawns a sub-agent, which production agents do regularly, the identity chain breaks. Every instance needs its own credential, scoped to a single tool call, with a lifecycle tied to a named human sponsor.
The second is audit. Once an agent delegates to a sub-agent, existing log trails stop answering the questions regulators will ask. Who consented. What the original purpose was. Whether consent survived the delegation hop. Most logs today tell you a service account did a thing. They do not tell you which human authorized it, through which chain, for what purpose, on what data.
The third gap is the one with no mature product category yet. Olivier calls it runtime policy: a separate engine, sitting outside the agent's reasoning loop, that evaluates every agent-to-tool call before it goes through. Should this agent, acting on behalf of this human, in this context, be allowed to invoke this tool with these arguments? Today, the agent itself often decides what tools it can call. As Olivier puts it: "Controls on the inmate, written by the inmate."
He is careful to say that no infrastructure vendor, Cerbos included, can make you EU AI Act-compliant. The August 2026 deadline (which may slip to December 2027 under provisional agreement) is not the real pressure. The architecture obligation is. Articles 9, 10, 12, and 13 of the Act require risk management, data governance, automatic logging, and transparency. None of those work without runtime controls at the agent-to-tool boundary.
The rebuild is already happening
The same week, VentureBeat reported on what Temporal Technologies SVP Engineering Preeti Somal is hearing from enterprise customers: they are coming back to rebuild their first-generation agents.
"They had to move really fast, but they didn't take care of the plumbing," Somal said. "Things crash and burn, and then they're back to rebuilding with the reliable foundation."
The pattern is familiar. Somal compared it to the lift-and-shift era of cloud migration, when enterprises moved workloads to AWS or Azure without redesigning the underlying architecture, then wondered why costs went up and reliability did not. "This rush to do AI in a world where you haven't even modernized your application reminds me a little bit of that lift-and-shift that happened in the cloud," she said.
The core problem is that production agents do things prototypes do not. They run for hours. They call multiple models. They interact with external systems. They accumulate state that gets expensive to recompute when something fails. And when a workflow crashes on step 8 of 12, most teams have no choice but to re-run the entire thing from step 1, paying the token cost for steps 1 through 7 a second time.
Temporal's answer is what Somal calls a "deterministic spine": orchestration software that tracks where the agent is, what it has done, and where to pick up after a failure. The LLM is the probabilistic brain. The spine is what makes it survivable.
What the convergence tells you
These three stories, a benchmark, a governance framework, and a field report, are not about the same thing on the surface. ITBench-AA measures model accuracy on operations tasks. Cerbos measures whether authorization exists at the tool boundary. Temporal measures whether workflows survive failure.
But they point to the same problem: the model is not the system. The model is one component in a pipeline that also needs identity, authorization, audit, state management, failure recovery, and cost visibility. Most production agents have the model and skip the rest.
The ITBench-AA benchmark puts a number on the model's ceiling: 47%. Gartner's May 26 prediction, that 40% of enterprises will decommission autonomous agents by 2027, puts a number on the business consequence. Cerbos identifies the specific architectural gaps. Temporal describes what the fix looks like in practice.
If you are evaluating AI agents for production, the question is not which model to pick. It is whether the pipeline around the model can handle the 53% of cases where the model gets it wrong, and whether you can prove to a regulator, an auditor, or your own security team that the agent's tool calls were authorized, logged, and recoverable.
That infrastructure does not exist yet in most stacks. The vendors, analysts, and practitioners are converging on what it should look like. The implementations need to catch up.
Sources:
- ITBench-AA: Frontier Models Score Below 50% on the First Benchmark for Agentic Enterprise IT Tasks, Artificial Analysis / IBM Research (May 30, 2026)
- "Authorization for AI agents: What to build before the EU AI Act deadline," Alex Olivier, Cerbos (June 1, 2026)
- "AI agents are entering their rebuild era as enterprises confront the reliability problem," VentureBeat / Temporal Technologies (May 29, 2026)
- "Gartner says applying uniform governance across AI agents will lead to enterprise AI agent failure," Gartner press release (May 26, 2026)