Your AI Agent Security Tests Are Wrong. New Research Proves It.
Cisco tested 15 AI models with multi-turn attacks. Success rates jumped up to 9x. Three reports confirm your security benchmarks are measuring the wrong thing.
By SpringVanta
Cisco just published research that should make every security team revisit their AI agent testing strategy. The company tested 15 frontier AI models from OpenAI, Anthropic, Google, xAI, and Amazon using multi-turn attacks instead of the standard single-prompt benchmarks that vendors rely on for their safety claims.
The results are ugly. Models that looked safe under standard testing fell apart when attackers were allowed to iterate.
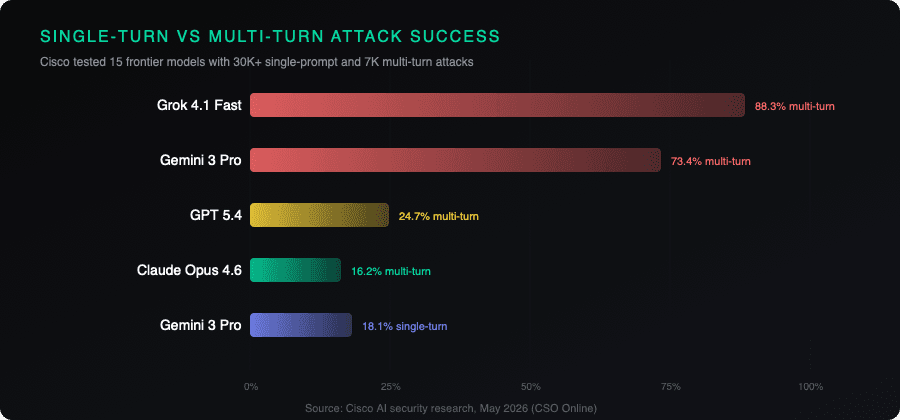
Google's Gemini 3 Pro went from an 18% single-turn attack success rate to 73% when the attacker used multi-turn conversations. OpenAI's GPT 5.4 jumped from 2.7% to 24.7%. xAI's Grok 4.1 Fast hit 88.3%.
Cisco ran over 30,000 single-prompt attacks and nearly 7,000 multi-turn attacks across 1,456 conversations. The attack techniques were not exotic: role-play, misdirection, incremental escalation, information decomposition. These are tactics any moderately skilled social engineer already uses.
The benchmark problem
Here's what bothers me about these numbers. When a vendor says their model has a "2.7% attack success rate," they're citing single-prompt tests. That number goes on the safety documentation. It goes into the procurement review. It goes into the risk assessment.
And it's off by an order of magnitude.
Cisco's research confirms what red-teamers have been saying informally for months: single-turn benchmarks systematically understate risk because real adversaries do not try once and give up. They iterate. They pivot. They decompose a harmful request into pieces that each look harmless on their own. The model grants each piece because each piece passes the safety check. The aggregate result does not.
Anthropic's Claude Opus 4.6 held up best in Cisco's tests, going from 3.6% single-turn to 16.2% multi-turn. That is a meaningful jump but a lot smaller than the competition. Still, even the strongest model was 4.5 times more vulnerable under multi-turn testing.
The visibility gap
The Cisco research dropped in the same week that TrueFoundry published survey data from 200+ enterprise AI leaders with a finding that compounds the problem: 54% of organizations cannot fully trace what their AI agents are doing. More than half have no centralized governance or control layer.
Google's Mahesh Kumar Goyal put it plainly in CSO Online's coverage: "Most enterprises have no inventory of the agents already running in production. They are trying to govern what they cannot see."
So here is the structural problem: your safety benchmarks are wrong (Cisco proved it), and you probably cannot see what your agents are actually doing in production (TrueFoundry confirmed it). That is not a gap. That is a chasm.
MCP becomes the blind spot
Cyberhaven added a third data point on May 29 with an analysis of six security risks in the Model Context Protocol. MCP is becoming the standard integration layer between AI agents and corporate data. Anthropic developed it. Microsoft, Google, and Salesforce have all adopted it. Your agents will use it.
Most enterprises have no inventory of which MCP servers are running in their environment. The protocol creates what Cyberhaven calls a "clean delivery path" for indirect prompt injection: attackers embed instructions in content that an MCP tool retrieves, and the agent follows those instructions because they arrived through a trusted channel.
The six risk categories Cyberhaven identified are worth knowing: uncontrolled data access and exfiltration, prompt injection via MCP tool responses, tool poisoning, excessive privilege and scope creep, authentication gaps between agents and servers, and shadow MCP integrations that security teams never approved.
If your team is deploying agents with MCP connectors and nobody has audited the server inventory, that is the first thing to fix.
What changed this week
Three independent sources, published within 72 hours of each other, all point to the same conclusion. Security benchmarks measure the wrong thing. Organizations lack the visibility to catch what the benchmarks miss. And the integration layer that connects agents to your data was not designed with security oversight in mind.
Cisco proved the technical gap. TrueFoundry quantified the organizational gap. Cyberhaven mapped the infrastructure gap. None of them coordinated. All of them agree.
What to do
If you are running AI agents in production or heading there soon, three concrete steps:
Audit your MCP surface. Find every MCP server your agents connect to. Document what data each one can access. If you do not have a list, you have a problem.
Add multi-turn testing to your security review. Single-prompt benchmarks are not sufficient. Cisco's methodology is public. Use it or something similar. At minimum, test whether your agents can be manipulated over multi-step conversations, not just single messages.
Build an agent inventory before building a governance framework. You cannot govern what you cannot see. The TrueFoundry data suggests more than half of organizations skip this step. Before you write governance policy, find out what agents are already running, what data they access, and what MCP integrations they use.
None of this is complicated. All of it is more work than most teams have done.
Sources: Cisco AI security research via CSO Online (May 27, 2026); TrueFoundry survey via CSO Online (May 28, 2026); Cyberhaven MCP security analysis (May 29, 2026); Sonatype on autonomous governance (May 27, 2026).