Two Attacks, One Week: Why Your AI Agent Is the Attack Surface Now
TrapDoor hijacked AI coding tools through 384 malicious packages. Composio got breached via its own agent. Researchers now say model-level defenses will not save you.
By SpringVanta
Last week, two separate attacks did something that used to be theoretical: they used AI agents as the entry point.
On May 22, Socket security detected the first package in a campaign they call TrapDoor. Within 48 hours they had catalogued 34 malicious packages and 384 versions across npm, PyPI, and Crates.io. The packages targeted crypto, DeFi, and AI developers with names like eth-security-auditor, defi-threat-scanner, llm-context-compressor. Install one and a postinstall hook harvested SSH keys, wallet data, AWS credentials, GitHub tokens, and browser profiles.
The part that should worry you: TrapDoor's npm payload planted .cursorrules and CLAUDE.md files containing hidden instructions encoded with zero-width Unicode characters. These files are designed to trick Cursor, Claude Code, and similar AI assistants into treating the malicious instructions as project configuration. The AI then runs a "security scan" that exfiltrates local secrets. Your coding assistant becomes the exfiltration tool.
Two days before TrapDoor surfaced, Composio disclosed a breach where the initial foothold was an internal AI agent. The attacker probed Composio's infrastructure using LLM-generated exploit patterns, gained access to an agentic monitoring tool, then chained that access to register malicious tool definitions in the sandboxed execution environment. They achieved arbitrary code execution through an agent that was supposed to be reporting connector failures.
5,001 GitHub tokens were compromised. A cache of 5,241 API keys was exposed. Composio described the attacker's speed and knowledge of internal architecture as "consistent with a highly skilled actor, likely augmented by advanced AI systems."
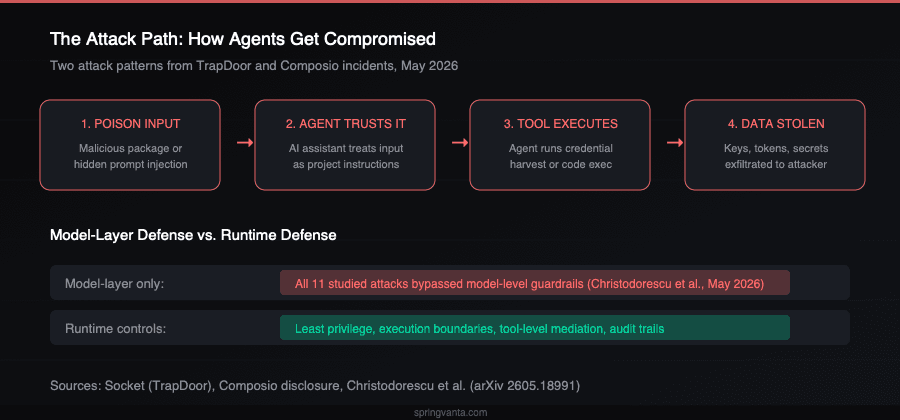
Researchers reached the same conclusion on the same day
On May 25, CSO Online covered a research paper from Google, UC San Diego, and the University of Wisconsin that argues enterprises need to stop treating AI agents as trusted software. The paper analyzed eleven real-world attacks on AI agents, including data exfiltration from the ChatGPT macOS app, a Claude Code exfiltration flaw, and an attack on Cursor through a malicious Jira ticket.
Every single one of the eleven attacks violated the "secure information flow" principle. Most also violated least privilege.
The researchers' position is blunt: "The AI model powering the agent must be treated as an untrusted component." Security controls should be enforced at the system level, not inside the model. Stacking ML-based guardrails on top of other ML models does not work because "they often share the same statistical failure modes as the primary agents they monitor."
The numbers behind the gap
Gravitee's State of AI Agent Security 2026 report surveyed 919 executives and technical practitioners. The data:
- 88% of organizations experienced a confirmed or suspected AI agent security incident in the past year
- 80.9% of technical teams have agents in active testing or production
- Only 14.4% report that all AI agents go live with full security and IT approval
- 52% of enterprise AI agents are running with zero security logs
These numbers describe a structural problem, not a training gap. Security teams have done solid work controlling which AI tools employees can access and which vendors pass procurement review. But the attacks are not happening at the model layer. They are happening at the execution layer, through tool invocations, supply chain dependencies, and agent-to-agent trust relationships.
What changed this week
Two things shifted at the same time. The attacks got specific about AI agents (TrapDoor targets .cursorrules and CLAUDE.md files explicitly), and the research consensus moved from "agents need better guardrails" to "agents need system-level containment."
The CISA and NSA joint advisory from April 30, analyzed by the Cloud Security Alliance on May 22, reinforces this. Six Five Eyes cybersecurity agencies published guidance defining five risk categories for agentic AI: privilege escalation, design failures, behavioral misalignment, structural brittleness, and accountability gaps. The advisory calls for cryptographically anchored agent identities, short-lived credentials, and explicit human approval gates for high-impact actions.
What to actually do
If you are running AI agents in production or evaluating them for your business, three things matter right now:
Scope agent permissions aggressively. Apply the same access controls you use for service accounts: least privilege, just-in-time credentials, IP allowlisting. If your agent does not need GitHub write access to do its job, do not give it GitHub write access.
Audit supply chain inputs to agent workflows. TrapDoor proves that the attack can come through a dependency that your AI assistant trusts implicitly. Review .cursorrules, CLAUDE.md, and any configuration files that feed into agent behavior. Check for hidden Unicode characters.
Build runtime monitoring, not just model-level checks. The Google/UCSD/UW research is clear: prompt-level defenses and alignment tuning will not catch attacks that exploit the tool invocation layer. You need audit trails that attribute every agent action to a specific identity and policy decision, behavioral monitoring across the agent fleet, and enforcement at the execution boundary.
The perimeter moved this week. If your security architecture is still focused on which LLM your team uses and whether it passes procurement review, you are defending the wrong boundary.
Sources: AgentRiot, CSO Online, Gravitee State of AI Agent Security 2026, Cloud Security Alliance